Ch. 8: Integrating Navigation with Search
This chapter describes interfaces to support navigation (or browsing) as part of the search process. Chapter 3 discusses theoretical models of browsing versus search as information seeking strategies, as well as the notion of information scent and information architecture. As mentioned there, one way to distinguish searching versus browsing is to note that search queries tend to produce new, ad hoc collections of information that have not been gathered together before, whereas navigation/browsing refers to selecting links or categories that produce pre-defined groups of information items. Browsing activities can include following a chain of links, switching from one view to another, in a sequence of scan and select operations. Browsing can also refer to the casual, mainly undirected exploration of navigation structures.
Navigation structures lend themselves more successfully to books, information collections, personal information, Web sites, and retrieval results than to vast collections such as the Web. Nonetheless, there have also been attempts to organize very large information collections such as the Web.
Category systems are the main tool for navigating information structures and organizing search results. A category system is a set of meaningful labels organized in such a way as to reflect the concepts relevant to a domain. A fixed category structure helps define the information space, organizing information into a familiar structure for those who know the field, and providing a novice with scaffolding to help begin to understand the domain. Category system structure in search interfaces is usually either flat, hierarchical, or faceted (this is discussed in detail below).
In search interfaces, categories are typically used either for selecting a subset of documents out from the rest, thus narrowing the results, or for grouping documents, dividing them into (potentially overlapping) subsets, but keeping the documents visible. They can also be used for ordering and sorting search results. Faceted category navigation integrated with keyword search has become especially successful for search over information collections.
In most browsing structures, a set of category labels is manually defined and documents are assigned to those categories, either by hand or automatically. However, in an attempt to avoid the need for manual category creation and assignment, clustering algorithms have often been explored to aid in the exploration of collections and retrieval results. The advantage of clustering is that the groups and labels are automatically derived from the document collection, but the disadvantage is that the outcome is usually less predictable and less understandable than that of category systems.
The following sections discuss interfaces for grouping search results and collections by flat categories, hierarchical categories (including table-of-contents structures), and faceted categories. Then the use of clustering for creating flat and hierarchical organizations is discussed. Finally, the relative merits of categories versus clusters are discussed.
8.1: Categories for Navigating and Narrowing
Many of today's Web sites have sophisticated, well-designed information structures that use categories to help the user navigate the site and narrow down the content to what is of most interest. In some specialized content domains (sometimes known as verticals), the top-level categories tend to become standardized across Web sites over time. (How this happens has not been studied; presumably the designers of major Web sites examine other sites' categories, as well as study their navigation and search logs to see what people are looking for. For some commercial sites, sellable products presumably help determine the categories.) For example, the top-level categories for U.S. sports Web sites are usually named after sports organizations, including NFL, MLB, NBA, NHL, etc. Table 8.1 shows the top-level categories for three major sports Web sites, used in the main navigation menu.
ESPN USA Today MSN/Foxsports Fantasy 1 1 12 NFL 2 3 1 MLB 3 2 2 NBA 4 4 3 NHL 5 5 4 ESPNU 6 - - College FB 7 6 6 Men's BB 8 8 7 Women's BB 9 8 7 NASCAR 10 - 5 Auto 11 9 - Golf 12 10 9 Soccer 13 - - Tennis 14 - 10 Boxing 15 - - AFL 16 - - Table 8.1 Categories as navigation aids for three major sports Web sites (espn.go.com, www.usatoday.com/sports, and msn.foxsports.com) as of Summer 2007. Numbers indicate the position, from left to right, across the navigation bar. Note the uniformity both in the names of the top-level categories and their positioning. The naming exceptions are that only ESPN distinguish Men's and Women's basketball (the other two names are College basketball and NCAA BK), and a distinction between College Football, NCAA FB, and College FB).
Not only are the top-level categories nearly the same, but the submenus for the different sports ( Teams, Statistics, etc.) are nearly identical as well. The categories serve a narrowing function; first navigating to MLB (Major League Baseball) and then to Teams shows information about baseball teams. Consequently, the categories keep similar types of information across different sports separated from one another; there is no way on these sites to see, say, statistics across all sports simultaneously. For the purposes of the users of most of these sites, that kind of comparison is not important, and so the restricted category structure works well.
As another example of category systems used for narrowing information content, Google has recently developed a system called Co-op in which experts manually assign category labels to Web pages for a limited set of topic areas (Health, Travel, Computers, etc.). Each topic, has a predefined set of categories associated with it, organized into facets. Facets in the Health topic include Drug Information ( drug uses, side effects, etc), For doctors ( research overview, practice guidelines, etc.), and Information type ( from medical authorities, alternative medicine, for patients, support groups, etc.). Figure 8.1 shows the results of a search on the query tamoxifen, after selecting the category Treatment within the facet Condition Information. These labels are currently only used for refining search results -- that is, they narrow the set of retrieved documents; they are not used to group the results, and currently the results may be refined with only one label at a time. Thus selecting Interactions within the Drug Information facet after selecting Side Effects replaces the latter query with the former.
Although this looks like the query term suggestions of Chapter 6, there are important differences. Rather than replacing the original query with a different term that may help refine the sense of the word (as in substituting Apple computer for the query apple), the Co-op method uses category metadata (manually) assigned to documents to determine whether to retrieve the documents in the selected subset (as opposed to running a keyword match).

8.2: Categories for Grouping Search Results
A weakness of many Web sites' navigation structure is that the Web sites do not integrate their browsing with their searching functions. For example, the Google Co-op system described above uses faceted categories only for narrowing search results; only one category's information can be seen at any time. The sports sites described above do not use their category systems to organize the results of keyword search. A search on Bonds mixes articles about the baseball player Barry Bonds with writings about the football player Mark Bonds. (However, these sites do sometimes group search hits by genres: breaking news versus older news versus blog posts and columnist's essays.)
For Web search, Chapter 5 shows some simple approaches to grouping retrieval results for highly ambiguous queries (see Figures 5.1 and 5.7), but much more power is needed for collection or site search, as there is ample evidence that it can be useful to organize search results by grouping hits according to the categories that the documents fall into.
Dumais et al., 2001 use a text categorization algorithm to classify Web pages into one of ten top-level general categories (e.g., Automotive, Computers & Internet, Entertainment & Media, Travel & Vacations, Shopping & Services, Society & Politics, and Not Categorized). They experimented with seven different ways of showing the search results, varying whether category groupings, category names, document titles, and document summaries were shown (see Figure 8.2). They evaluated the results by timing how long participants took to find the first relevant document for each of several pre-determined queries. The most significant result was that the category groups were responsible for the biggest time savings. Results listings that grouped categories together but did not label the categories performed nearly as well as results that showed groups with labels, and far better than linear results listings that contained category names beneath each search result. In fact, no significant difference was seen between a linear listing of search results and the same listing with category names alongside each search hit. (For many years, major Web search engines showed category labels drawn from manual directories alongside search results. That is no longer common practice, and the results of this study support this omission.) Subjective results indicated a strong preference for the category grouping interfaces, although the interface that showed groups but no group labels was disliked, despite the fact that it helped achieve higher scores in the study.

(a)

(b)
Further analysis revealed that most of the timing gain came from those queries for which the relevant results were not in the top 20 search results in the linear listings. This means that, in these cases, a category selection operation moved relevant documents up from farther down in the results listing, showing them alongside similar documents.
It is important to note, however, that the queries for the Dumais et al., 2001 study were in fact carefully designed to maximize the disambiguation effects of category usage. For example, one task was to Find the home page for the band called “They Might be Giants”. The query in this case was giants, which is a rather unrealistic formulation for a query on a band of this name (titles of books, movies, musical groups, etc., are common web queries). Another task was to Find the Giants Ridge Ski Resort, and again the query that was input for the participants was giants, which is also an unlikely query for this information need. Thus the large timing differences are most likely artificial and would probably become much smaller or could even disappear with a more realistic set of queries. Studies of clustering (see below) suggest that grouping is less effective for unambiguous queries.
A more recent study by Kules and Shneiderman, 2008 exposed participants to two versions of an interface: the baseline with standard search results listings and the experimental design that used the same results listings but categorized hits in a list of categories with query previews on the left hand side. Participants were 24 journalism students who were asked to conduct Web searchers to find ideas for articles to write on four different topics. The top 100 pages of a search engine's results were classified automatically into top-level categories drawn from the Open Directory Project (ODP), as well as into government and geographic categories.
The experimenters found no significant differences in the quality of the ideas generated, but on subjective scales participants found the categorized interface more appealing and the results felt more organized than the baseline. Participants also viewed a broader portion of the results listings in the category interface, an effect which is echoed in other studies discussed below (Käki, 2005c, Zamir and Etzioni, 1999). Several participants commented that they changed their search tactics by looking at the category listings before looking at the results listings, or using it as a backup when they felt stuck. However, participants voiced discontent with category labels that were not representative of the expected meaning of the underlying documents, e.g., categorizing a news story about human smuggling under TV because the Web page was from the BBC. Additionally, many of the categories were vague or general (e.g., Reference, Society), which lessened the usefulness of the category system. The participants did not find the category interface more difficult to use, but two participants commented on the complexity of the categories and one asked for a method to hide them.
More evidence for the value of grouping search results by categories is provided in the section on faceted navigation.
8.3: Categories for Sorting and Filtering Search Results

In addition to being used for navigating content within Web sites and grouping search results, categories can be used for sorting search results, that is, for reordering results according to one or more attributes' values.
Some sorting interfaces allow for ordering along only one dimension at a time, as seen in the lower region of the eBay Express example in Figure 8.12. The user has the option of sorting the search results by Best Selling, Best Match, or Price. Other sorting interfaces present results in a sortable-column format in which results can sorted by one dimension after another, usually by clicking on the label of the column, as seen in Figure 8.3 and in Figure 10.17(a) of Chapter 10. Figure 8.3 shows the Phlat interface (Cutrell et al., 2006b) for navigating and searching personal information, including email, calendar events, locally stored documents, and recently visited Web pages. The results section on the right hand side allows the user to sort search results according to the title (by alphabetical order), by date, by author/sender, by recipient name, and by a number of other attributes not shown in the figure. As is common in file browser interfaces, a click on the title of the column sorts the contents by the corresponding attribute, toggling between ascending and descending sort order. An advantage of the sortable-column format is that after sorting along one dimension, such as date, the user can sort along another, such as author, while retaining the date sort order from the prior sorting action within each author's message list (this is referred to as stable sorting).
Sorting is especially useful for attributes which have a naturally understandable sequential order (attributes with real, integer, or ordinal values); for instance, it makes sense to see products ordered by increasing price or email ordered by decreasing recency. Sorting does not work well if the attribute of interest does not have an inherently meaningful ordering. For example, people's names are often listed alphabetically, and it is easy to select or look up a name within alphabetical order, but scanning people's names according to alphabetical order is not meaningful in the same way as scanning products by increasing price. That is, there is usually no meaning inherent in showing messages from Charles Adams immediately adjacent to messages from Douglas Adams. (These ideas are discussed in more detail in Chapter 10.)
For nominal attributes which do not have a meaningful order, it can be more useful to provide users with a filtering function, to be used in conjunction with sorting. Filtering is the application of a category or attribute to select out from the search results only those items that meet the filtering criterion. (Sorting rearranges but does not remove any results.) Filtering is thus used to eliminate some records to help focus on categories of interest. In the Phlat example of Figure 8.3, after doing an initial query on the keyword bike, the user chose a filter that selects only messages labeled as Personal. In this example, the user also chose a file type filter, restricting results to only email and calendar hits. Finally, the results were sorted according to date, showing the most recent items first.
Activating a filter is functionally similar to navigating via a category, but differs conceptually in terms of interface design and expectations. While both perform narrowing functions, a filter is intended to be toggled on and off, to manipulate the subset of search results without disturbing the other constraints on the results, while selecting a topic category is meant to hide the other category choices and reduce the set in view.
In a longitudinal study of the use of the Phlat system by more than 200 people over an 8-month period, Cutrell et al., 2006b found that 47% of all queries used some kind of filter. Of these, the most common were people followed by file type and then date (note however that the default sort order was date; an earlier study (Dumais et al., 2003) showed that date/time was the preferred organization for personal information collections). One third of all searches that used filters used more than one filter, and 17% of searches used only filters, with no query term at all.

8.4: Organizing Search Results via Table-of-Contents Views
The sections above have described the use of flat, or linear, categories for navigating, sorting, filtering, and grouping of search results. Another common information organization structure is that of the hierarchy or tree structure. One simple version of the hierarchy is the table-of-contents view used in books and other information systems. A number of research systems have put forward the idea of supporting search results organization by making use of a table-of-contents (TOC) structure.
The SuperBook system (Landauer et al., 1993, Egan et al., 1989a, Egan et al., 1989b) pioneered a number of search user interface ideas, but its major emphasis was to make use of the structure of a large document to display query term hits in context. The table of contents (TOC) for a book or manual were shown in a hierarchy on the left hand side of the display, and full text of a page or section was shown on the right hand side. The user manipulated the table of contents to expand or contract the view of sections and chapters. A focus-plus-context mechanism (see Chapter 10) was used to expand the viewing area of the sections currently being looked at and compress the remaining sections. When the user moved the cursor to another part of the TOC, the display changed dynamically, making the new focus larger and shrinking down the previously observed sections.
After the user specified a query on the book, the search results were shown in the context of the TOC hierarchy (see Figure 8.4). Those sections that contain search hits were made larger and the others were compressed. The query terms that appeared in chapter or section names were highlighted in reverse video. When the user selected a page from the TOC view, the page itself was displayed in the right hand side and the query terms within the page were highlighted in reverse video.

To evaluate the interface, the SuperBook system was compared against using paper documentation and against a more standard online information access system (Landauer et al., 1993). Participants were asked to complete several kinds of carefully selected tasks: browsing topics of interest, citation searching, searching to answer questions, and searching and browsing to write summary essays. For most of the tasks participants were faster and more accurate or equivalent in speed and accuracy using SuperBook over a standard system. The investigators examined the logs carefully and hypothesized plausible explanations for differences between the systems.
After the initial studies, they modified SuperBook according to these hypotheses and usually saw improvements as a result (Landauer et al., 1993). The usability studies on the improved system showed that participants were faster and more accurate at answering questions in which some of the relevant terms were within the section titles themselves, but they were also faster and more accurate at answering questions in which the query terms fell within the full text of the document only, as compared both to a paper manual and to an interface that did not provide such contextualizing information. SuperBook was not faster than paper when the query terms did not appear in the document text or the table of contents. This and other evidence from the SuperBook studies suggest that query term highlighting is at least partially responsible for improvements seen in the system (see the related discussion in Chapter 5).
Several researchers have experimented with placing Web search results into a TOC-like format, using the structure of web sites' hyperlinks. Figure 8.5 shows an example from the Cha-Cha system (Chen et al., 1999, Chen and Hearst, 1998). This system differs from SuperBook in several ways. On most Web sites there is no existing real table of contents or category structure, and an intranet like those found at large universities or large corporations is usually not organized by one central unit. Cha-Cha uses link structure present within the site to create what is intended to be a meaningful organization on top of the underlying chaos. After the user issues a query, the shortest paths from the root page to each of the search hits are recorded and a subset of these are selected to be shown as a hierarchy, so that each hit is shown only once. The AMIT system (Wittenburg and Sigman, 1997) also applied the basic ideas behind SuperBook to the Web, but focused on a single-topic Web site, which is more likely to have a reasonable topic structure than a complex intranet. The WebTOC system (Nation, 1997) was similar to AMIT, but focused on showing the structure and number of documents within each Web subhierarchy, and was not tightly coupled with search.

In the Dynacat system (Pratt et al., 1999), a set of categories was pre-selected from a large taxonomy, in a particular domain. A set of query types was also pre-determined. In this particular case, the domain studied was cancer, so sample query types are “What are the potential complications of Procedure X?” or “What are the ways to prevent Condition Y?”. The retrieved documents were organized according to which types of categories, were known in advance to be important for a given query type. Results were grouped into relevant category hierarchies such as Behavior, Nutrition, Chemicals and Drugs, etc. (see Figure 8.6). The left window showed the categories in the first two levels of the hierarchy, providing a table of contents view of the organization of search results. The right pane displayed all the categories in the hierarchy and the titles of the documents that belong in those categories. A 15 person between-participants usability study comparing this tailored category based interface to a linear list and a polythetic clustering interface (see below) found a strong subjective preference for category organization over both of the other search results interfaces.
Despite the experimental evidence in favor of TOC structures, they are still not widely used to organize search results or online book search Web sites.
8.5: The Decline of Hierarchical Navigation of Web Content
In the early days of the Web, hand-built category hierarchies (web directories) such as those supplied by Yahoo and LookSmart and more recently the open-source directory ODP, were very popular ways to navigate the Web (Pollock and Hockley, 1997). Figure 8.7 shows the Yahoo directory circa 1997, when it was heavily used.

As the growth in the number of Web sites accelerated and the accuracy of search engines improved, the importance of such general directories declined markedly. In addition to the improvement in web search ranking, this decline is probably linked to the poor navigability of the directory Web sites. Such hierarchies are difficult to navigate in large part because to accurately describe information, different categories often need to be mixed together. In particular, for the Yahoo directory, content categories are often intermixed with categories describing location and categories describing commercial concerns. This mixing of category types would lead to complex navigation paths for finding information. Consider the following sequence of links that must be traversed to find a kayaking Web site called Outdoor Adventures (www.kayaking.com) from dir.yahoo.com:
Directory > Regional > U.S. States > California > Cities > Lotus > Business and Shopping > Paddling
The Yahoo directory does have more direct paths to other kayaking web sites, for example,
Directory > Recreation > Outdoors > Paddling > Canoeing and Kayaking
but following this path will not lead the user to the Outdoor Adventures Web site. The user can take a different path:
Shopping and Services > Outdoors > Paddling
but this yields yet a different set of Web sites. These convolutions arise because of the difficulty of modifying hierarchy and retaining semantically consistent labels within hierarchy. It appears that, although hierarchical structures are commonly used and are useful when applied to smaller collections, as a navigation structure, they become unwieldy when applied to very large collections. Classification of information items more naturally requires access via multiple category starting points; this alternative is discussed below.
8.6: Faceted Navigation
A problem with assigning documents to single categories within a hierarchy is that most documents discuss several different topics simultaneously. Text consists of abstract discussions of ideas and their inter-relationships. It is a rare document that is only about trucks; instead, a document might discuss recreational vehicles, or the manufacturing of recreational vehicles, or for that matter the trends in manufacturing of American recreational vehicles in Mexico before vs. after the NAFTA agreement. The tendency in building taxonomic hierarchies is to create ever-more-specific categories to handle cases like these. A better solution is to describe documents by a set of categories, as well as attributes (such as source, date, genre, and author), and provide good interfaces for manipulating these labels.
This use of what is known as faceted metadata provides a usable solution to the problems with navigation of strict hierarchies. The main idea is to build a set of category hierarchies each of which corresponds to a different facet (dimension or feature type) that is relevant to the collection to be navigated. Each facet has a hierarchy of terms associated with it. After the facet hierarchies are designed, each item in the collection can be assigned any number of labels from the facet hierarchies. The resulting interface is known as faceted navigation, or sometimes as guided navigation. An alternative design, usually known as parametric search, requires the user to select a number of attributes from drop-down menus all at once, thus often leading to empty results sets. (For instance, at a Web site selling shoes, selecting women's shoes of size 4.5, width M, color black, and price to yields no results and provides no suggestions as to which attributes to remove.) For this reason, parametric search has largely fallen out of favor and been replaced by faceted navigation.
8.6.1: The Flamenco Faceted Navigation Interface

Faceted classification and faceted navigation are now widely used in web site search and navigation. In research on the Flamenco project, Hearst et al. (Hearst, 2000, Hearst et al., 2002, Yee et al., 2003, Hearst, 2006b) described the importance of faceted classification systems for web site navigation, and designed and studied a series of user interfaces to support faceted navigation for everyday users. The overarching design goals of the Flamenco project were to support flexible navigation, seamless integration of browsing with directed (keyword) search, fluid alternation between refining and expanding, avoidance of empty results sets, and at all times allowing the user to retain a feeling of control and understanding.
Another of the Flamenco project's goals was to promote the idea of faceted navigation in online systems, as an alternative to the hierarchical focus of Web site structure, and in response to the failure of subject searching in online catalogues (Larson, 1991, Hert et al., 2000). The term “faceted” was chosen by this project to reflect the underlying spirit of the idea from library science. Ranganathan, 1933 is often credited with introducing the idea with his colon classification system, which suggested describing information items by multiple classes, and Bates, 1988 advocated for faceted library catalogue representations in the 1980's. (Of course, how to use such systems in user interface was not addressed by Ranganathan, 1933, and Bates, 1988's view was restricted to that of TTY-based interfaces.) It should be noted that the Dewey Decimal system, often used in local libraries, has aspects of facet analysis because it combines multiple categories into one description string (Maple, 1995), but it does not allow for the flexible application of ordering and combination of categories that online faceted navigation affords.

Hearst et al., 2002 describe faceted metadata as being composed of “orthogonal” sets of categories, meaning each category describes a different, usually independent aspect of the information items. For example, in the domain of fine arts images, possible facets might be Media (etching, woodblock, ceramic, etc.), Locations (Asia, North America, Europe, etc.), Animals & Plants, Earth & Sky (mountains, rivers, clouds, etc), as well as information about the art, including artist names, time of creation, etc. A facet may be flat (“by Pablo Picasso”) or hierarchical (“located in Vienna > Austria > Europe”). A facet may be single-valued or multi-valued. That is, the data may allow at most one value to be assigned to an item (“measures 36 cm tall”) or it may allow multiple values to be assigned to an item (“uses oil paint, ink, and watercolor”). Portions of the hierarchies within a facet are sometimes referred to as the facet's subcategory or subhierarchy.
In a faceted search interface, labels are assigned to items from the collection. Figure 8.8 shows the faceted metadata associated with a woodcut by the Japanese artist Inoue Yasuji entitled “Toshagu Shrine, Ueno.” Within the Media facet, it has been assigned the category label Print > woodcut, within the Location facet it is assigned Asia > Japan. The painting contains a depiction of a snowy scene at night, with a Torii gate in the foreground through which runs a road leading to a red shrine in the background. Categories have also been assigned from the facet Heaven and Earth and Built Places as well as Shapes and Colors > Color > Red and Objects: Lighting > lantern. Because this object is indexed under these different, separate categories, a user can navigate to this image in a number of different ways.

For example, the user might start by selecting the Location facet, and within this, select Asia, and then the subcategory Japan. Figure 8.9 shows the results of this navigation. There are 538 pieces of art in this subcollection. The facets are shown on the left hand side, indicating with query previews (Plaisant et al., 1997b) how many of each kind of media (Drawing, Print, etc.) are in the collection, as well as the proportion of images from each media type, the number of prints whose images contain different object types and different building types. The documents that match the query are shown in the right hand pane. The user may now choose to navigate via a different facet, such as Built Places, and select Road (see Figure 8.10), and then grouping by the subcategories of Road, showing images containing Paths, Railways, etc.
A key component to successful faceted search interfaces is the seamless integration of keyword search. In this example, if the user now chooses to issue a keyword query, such as shrine, the category structure is retained; the keyword search is done over the metadata and text associated with the current result set; the resulting narrowed result set is again grouped by the facet categories (see Figure 8.11). These results include the image of the Toshagu Shrine (see Figure 8.8). Looking again at the metadata assigned to that artwork, the user may choose to make a lateral move within the collection, by clicking on lantern to see all artworks assigned this term.
This example is intended to illustrate the ease with which the user can navigate through the collection, with keyword search tightly integrated with the category system, and both narrowing and expanding of choices part of a smooth interaction flow.

Many important design details must be done well in order to ensure that a content-rich navigation system like Flamenco is easy to use. The graphical depiction of a users' navigation history or trail is often referred to as a breadcrumb. In standard Web site usage, breadcrumbs simply record the sequence of actions that the user has taken within the query session, and thus mix and match fields of various types (see Chapter 7). Faceted systems should instead keep the path within each facet in a separate visual component. This both reinforces the notion of the query consisting of a conjunction of different categories at different levels of hierarchy, and allows for flexible expansion of the query, since the user can eliminate an entire facet by clicking on the iconic x or “delete” link, or expand up within a category by clicking on a parent term. In Figure 8.9 this would mean generalizing from Japan to Asia by clicking on the latter link in the breadcrumb.
There is a question of how to expose the hierarchical categories without crowding the display or confusing the user. Flamenco adopted a step-by-step drill-down approach in which the level just below the currently selected level is visible, along with a trail indicating the higher level concepts positioned just above the labels. In addition, when the mouse hovers over a label, its immediate children are displayed in a tooltip, so the user can in fact see three levels simultaneously (see Figure 8.9).
Hearst et al. (English et al., 2001, Hearst et al., 2002, Yee et al., 2003) conducted a series of usability studies that found that participants like and are successful using hierarchical faceted metadata for navigating information collections, especially for browsing tasks. In one study (Yee et al., 2003), 32 art history students evaluated the Flamenco design in comparison with a baseline Google images-type interface for navigating a fine arts museum image collection containing about 35,000 items. The tasks were designed to reflect the contents of the collection and the art history background of the students. Participants completed four tasks on each interface, two structured and two unstructured. One of the structured tasks used metadata categories clearly visible in the start page and facet labels, but the other was carefully worded so as not to correspond to the wording of any facet.
Each participant used both interfaces (order was balanced), and filled out a questionnaire immediately after finishing each interface individually. Participants were significantly in favor of the faceted interface for the measures of “easy to use,” “easy to browse,” “flexible,” “interesting,” and “enjoyable.” For “simple” and “overwhelming,” there was no significant difference between the two designs, which is surprising given how much more information is shown in the Flamenco interface. The order in which interfaces were viewed had a strong effect on these ratings. When the faceted design was viewed first, the interface ratings for the baseline were considerably lower than when the baseline was the first interface shown.
At the end of the study, participants were asked to compare the two interfaces directly. For finding images of roses (a simple, single-facet task), about 50% preferred the baseline. However, for every other type of searching, the Flamenco interface was preferred: 88% said that Flamenco was more useful for the types of searching they usually do and 91% said they preferred Flamenco to the baseline overall. Those who preferred the baseline commented on its simplicity and stated that the categories felt too restrictive. These results were especially notable given that the faceted interface was an order of magnitude slower than the baseline (although participants did remark negatively about the slowness).
Some participants at the start of the study said they considered themselves the type of information seeker who like to use keyword search rather than select links. These participants did indeed start out with keywords, but as they became more familiar with the system, started initiating their tasks using links rather than keyword queries.
There are some deficiencies with the faceted paradigm. If the facets do not reflect a user's mental model of the space, or if items are not assigned facet labels appropriately, the interface will suffer some of the same problems as directory structures. The facets should not be too wide nor too deep (with exceptions for long lists such as author names that cannot be organized meaningfully) and the interface must be designed very carefully to avoid clutter, dead ends, and confusion.
8.6.2: Faceted Navigation at eBay Express
Faceted navigation has become the de facto standard way to support the integration of browsing and search on information-rich Web sites, ranging across collections as diverse as the WebMD health care Web site, the Dell Web site for purchasing computers, and the online catalog at Michigan State university (see Figure 8.15).
One site that had some particularly interesting design choices is the eBay Express online shopping interface (although eBay Express is no longer supported, a similar interface has since been adopted by the Yelp local reviews Web site, and the example is instructive). The designers determined in advance which subset of facets were of most interest to most users for each product type (shoes, art, etc.), and initially exposed only four of these fully, listing additional choices on one compact line below (see Figure 8.12). This interface positions the expanded facets across the top of the screen, in the “sweet spot” (the region of a Web page that users tend to look at first since it usually contains the most important content on the page). After the user selected a facet, one of the compressed facets from the list below was expanded and moved up to the end of the line (right hand side) of the expanded facets. For instance, in Figure 8.12, the initial expanded facets were Artist, Genre, Album Type, and Price, but the list was adjusted to account for the fact that two of these have been selected. The ordering of the facets in the query breadcrumbs reflected their order of selection by the user.
This interface also limited the number of labels shown for each facet, and customized which facets were shown on the basis of the type of information. In Figure 8.12, the labels beneath the Genre facet listed the four most common genres of music in the Boxed Set albums. Within these four, the genres were listed in alphabetical order. By contrast, the Price facet showed price ranges in ascending numerical order.
In this system, if a label within a hierarchical facet was chosen, the next level was shown as a separate facet. For example, in Figure 8.12, the user chose two labels: the first as Album Type > Box Set and the second was Genre > Jazz. Below the query were shown the available subcategories for the selected genre, Jazz. The facet name was Sub-Genre and the relevant labels included Big Band, Swing, Bop, Latin Jazz, and so on.

eBay Express had a particularly interesting approach to handling keyword queries. The system attempted to map the user-entered keywords into the corresponding facet label, and simply added that label to the query breadcrumb. For example, a search on “Ella Fitzgerald” created a query consisting of the Artists facet selected with the Ella Fitzgerald label. Search within results was accomplished by nesting an entry form within the query region. The eBay Express team commissioned third-party usability assessments that found that users understood these innovative aspects of the faceted interface design (Hearst et al., 2006).
8.7: Navigating via Social Tagging and Social Bookmarking
Another likely reason for the decline in popularity of hand-built classifications of Web content is that they cannot keep up with the contents of the Web. The early directories such as Yahoo and LookSmart were closed systems that only allowed employees of their respective companies to determine which categories Web pages fell into. The ODP system is open and allows contributors from all over the internet to donate content. However, annotation is time consuming as users must navigate a complex hierarchy and carefully consider which category to place a Web page into.

An important and growing alternative to Web directories are social bookmarking sites which allow any user to assign any category label to web pages. These category labels are usually referred to as tags. A user may assign any number of tags to an item, and can use any label that they think of, as opposed to having to determine the one “proper” category from within a hierarchy to assign. The popularity of tagging (or folksonomies, as user-generated tag systems are also known) is largely attributable to the relatively low cognitive overhead required in assigning tags without the need to refer to a controlled vocabulary, and to the ease with which multiple labels may be assigned. When a user tags a Web page, they simultaneously save the page to their own personal collection. Social bookmarking Web sites have search engines built in and are easily accessible from any networked computer, unlike bookmarking facilities provided by Web browser software. Thus, social bookmarking sites have distinct advantages over Web browser bookmarks for the individual assigning the labels, and so tagging is an activity that helps the labeller directly, and as a side-benefit, produces content that is useful for other people.
Figure 8.13 shows the results of a search on the tag kayaking on the social bookmarking site delicious.com. In this view the seven most popular sites are shown. Unfortunately, the search interfaces for social tagging sites tend to be lacking; on delicious.com, the site is rather limited in its search options, allowing the user to view only the few most popular sites or else view all sites labeled with a tag in terms of recency of labeling by any user. The site also does not allow users to see all tags associated with a given site. It does however provide a list of related tags; most likely these are tags that are co-assigned to the same items as the target tag.
The dogear system (Millen et al., 2006) provides more powerful navigation of tag structures within a social bookmarking site that is meant to be used within an organization's intranet. Figure 8.14 shows the bookmarks corresponding to first selecting the user named Jack Russell's tags, and then selecting both the design and the css tags within this set. Other tags associated with Jack Russell's bookmarks, but which are not applicable to the currently selected subset are shown under the “Jack's Tags” heading. The “People” tab in the upper left hand side of the interface shows bookmarks associated with the currently selected tags, but assigned by other people within the organization. Thus tags in this design act as faceted categories; the user can remove the tag css from the breadcrumb to expand the set of selected bookmarks to all those about design and then select another associated tag to narrow the set along another dimension.

Some interfaces are experimenting with a blend of structured facets and user-generated tags. Figure 8.15 shows a university library catalog which allows navigation according to traditional structured metadata such as publication year and collection, as well as narrowing by user-generated tags.

8.8: Clustering in Search Interfaces
A disadvantage of category systems is that they require the categories to be assigned by hand or by an algorithm. Automated methods exist for created faceted hierarchies (Stoica et al., 2007, Dakka and Ipeirotis, 2008) and assignment of documents to categories works reasonably well for limited category sets (Sebastiani, 2002), but fully automated information organizations remain appealing to system developers.
Many attempts to display overview or grouping information have focused on automatically extracting the most common general themes that occur within the collection. These themes are derived via the use of unsupervised analysis methods, usually variants of document clustering. Clustering refers to the automated grouping of items according to some measure of similarity. In document clustering, similarity is typically computed using associations and commonalities among features, where features are usually words and phrases (Cutting et al., 1992) ; the centroids of the clusters determine the themes in the collections. The greatest advantage of clustering is that it is fully automatable and can be applied to any text collection without manual labeling.
Kummamuru et al., 2004 make a distinction between monothetic and polythetic clustering, where monothetic clusters are based on a single shared feature, while polythetic clusters determine membership based on multiple shared features, thus grouping documents by overall similarity (this includes K-means and agglomerative clustering algorithms (Willett, 1988) ). Early work in document clustering for search results interfaces was done with polythetic clusters, as seen in the Scatter/Gather system (described below), but more recent work suggests that monothetic clusters may be easier for users to understand, since the criterion for cluster membership is relatively transparent. The choice of clustering algorithm influences which clusters are produced, although there is little agreement about which algorithms work best (Willett, 1988), particularly for presentation in search interfaces.
8.8.1: Clustering via Inter-Document Similarity
The best-known and earliest research on document clustering for search user interfaces is the Scatter/Gather project (Cutting et al., 1993, Cutting et al., 1992). The goal was to automatically and dynamically create a TOC-type structure for navigating the contents of a text collection, by clustering documents into topically-coherent groups, and presenting descriptive textual summaries to the user.
Document terms were weighted and represented as vectors, and clustering was done via hierarchical agglomerative clustering, which is a polythetic approach. The summaries consisted of topical terms that characterized each cluster generally, and a set of typical titles that hinted at the contents of the cluster. Informed by the summaries, the user could select a subset of clusters (gather) that seem to be of most interest, and re-cluster their contents (scatter). Thus the user could examine the contents of each subcollection at progressively finer granularity of detail. The reclustering was computed on-the-fly; different themes are produced depending on the documents contained in the subcollection to which clustering was applied.
A usability study by Pirolli et al., 1996a showed that the use of Scatter/Gather on a large text collection successfully conveyed some of the content and structure of the corpus. However, that study also showed that Scatter/Gather without a search facility was less effective than a standard similarity search for finding relevant documents for a query. That is, participants allowed only to navigate, not to search over, a hierarchical structure of clusters covering the entire collection were less able to find documents relevant to the supplied query than subjects allowed to write queries and scan through retrieval results.
It seems to be more useful to integrate a document clustering method like Scatter/Gather with conventional search technology by applying clustering to the results of a query to organize the retrieved documents (see Figures 8.16 and 8.17). An off-line experiment by Hearst and Pedersen, 1996 suggested that clustering may be more effective if used in this manner. The study found that documents relevant to the query tended to fall mainly into one or two out of five clusters, if the clusters were generated from the top-ranked documents retrieved in response to the query. The study also showed that precision and recall were higher within the best cluster than within the retrieval results as a whole. The implication was that a user might save time by looking at the contents of the cluster with the highest proportion of relevant documents and at the same time avoiding those clusters with mainly non-relevant documents. Thus clustering of retrieval results might be useful for helping direct users to a subset of the retrieval results that contain a large proportion of the relevant documents.


General themes do seem to arise from document clustering, but the themes are highly dependent on the makeup of the documents within the clusters (Hearst, 1998, Hearst and Pedersen, 1996). The unsupervised nature of clustering can result in a display of topics at varying levels of description. For example, clustering a collection of documents about computer science can result in clusters containing documents about artificial intelligence, computer theory, computer graphics, government, and legal issues. The latter two themes are more general than the others, because they are about topics outside the general scope of computer science. Thus clustering can result in the juxtaposition of very different levels of description within a single display. Usability study results suggest that users dislike organizations that show inconsistent levels of description (Chen et al., 1998).
Another problem with clustering by overall document similarity is that documents are similar to (and different from) one another in many different ways simultaneously. Consider articles about the auto industry. Should an article about cars that use alternative energy be placed in an energy cluster if it is about meeting the legal requirements for emissions standards, or in a legal category? What if there are articles about Japanese versus German cars' emissions? Should these be grouped by geolocation or into the alternative energy group, or somewhere else? As discussed below, usability studies suggest that polythetic clustering is dispreferred compared to organizing results by hand-built category labels which allow mixing and combining of topics.
Scatter/Gather shows a textual representation of document clusters. Numerous researchers attempted to show document clusters graphically; these are discussed in Chapter 10.
8.8.2: Clustering According to a Shared Common Term
Monothetic clustering algorithms (Käki, 2005b, Kummamuru et al., 2004) build clusters around dominant phrases, which give rise to more understandable labels. Käki, 2005b performed several usability studies using a monothetic clustering algorithm interface called Findex (see Figure 8.18). These included a longitudinal study in which 16 participants used the interface for two months each. Log analysis on this system revealed that on average the participants chose to click on the clusters for 26% of their queries. Furthermore, the proportion of cluster use increased over the time of the study, becoming as high as 39% of the queries towards the last weeks. For those queries for which clusters were used, the participant selected 2.3 clusters on average. When asked how often the clusters were useful, most responded “sometimes.” Participant comments also suggest that the clusters helped them quickly determine whether their query produced useful results or not, presumably because the cluster terms provide a quick summary of the kinds of results returned.
An analysis of the queries for which clusters were selected suggested that they are helpful primarily for moving documents that are low in the standard search rankings up higher. This happened on those occasions in which the query was ambiguous and the primary sense was not shown near the top of the search results, or when the query was specified very generally. Six of the participants explicitly commented that clusters were helpful when the query was vague, general, or contained words with multiple meanings. A particularly interesting result of this study is that 45% of the participants reported that they began to use less precise query terms as they became accustomed to the cluster interface, and 27% said they thought less about query formulation than before.
The Findex clusters seemed beneficial for exploratory tasks in which more than one result was desired, because participants selected multiple documents more often after clicking on a cluster than when selecting from the straight results listing. Participants also spent almost twice as long selecting the first search result when they used clusters versus when using the results listing. This may be due to the cognitive overhead of interpreting the clusters, but may also suggest that clusters were used in those cases when finding the desired result is more difficult. The latter explanation is supported by some of the participants' comments about how and when they used the clusters.

An important question for interfaces that group search results is: how many groups should be shown? The answer probably differs for faceted navigation interfaces that allow selection of multiple categories as opposed to clustering or categorization interfaces that only permit drilling down into one group at a time.
Käki, 2005c performed a controlled experiment which compared presenting 10, 20, or 40 groups using monothetic clusters. The 27 participants were asked to find as many relevant documents as possible for a set of pre-written queries, within a one minute time limit. When 40 groups were presented, participants took longer to select the first relevant document, took longer to finish the tasks, and selected fewer relevant documents than with 10 and 20 groups, although the differences were not statistically significant. Participants' subjective scores stated that 20, and especially 40 groups were perceived as too many. This echos results seen with automated term suggestion interfaces (see Chapter 6). These and other results can be summarized as fewer is better from the perspective of general users.
The Findex longitudinal results echo some results found by Dumais et al., 2001 described above, in the role of grouping results by a small set of categories. These results also echo what was found by Zamir and Etzioni, 1999 when studying logs of their Grouper system. Grouper used a hybrid of polythetic and monothetic clustering. Documents were grouped according to sets of shared phrases, and those phrases they shared, along with the percentage of document in the group that contained those phrases, were displayed to the user as the cluster description. As is standard in polythetic clustering, two documents could be in the same cluster even if they did not share a common phrase, but did share phrases with other documents in the cluster. In this algorithm, documents frequently fell into multiple clusters, which is not standard for polythetic document clustering.
In a log analysis, Zamir and Etzioni, 1999 found that multiple search results were clicked on more often when one or more clusters were selected. They also found that more time elapsed before the first document was selected when using the clusters than when selecting from the straight search results. These two points together were also seen in the Findex study, suggest that finding the first relevant document requires more effort with the grouping interface, but finding additional interesting documents requires less effort than with the ranked results listing.
In another study Wu et al., 2003 selected terms from document snippets and organized these terms into a subsumption hierarchy, highlighting the query terms in the retrieved summaries. Nineteen undergraduate participants used the system for their own queries and had a significant preference for the system with the grouping interface compared to its linear interface (although it may be the case that the linear interface was inferior to that of standard search engines; it was not described in detail). In a second followup study, 6 participants' queries were logged and studied in detail. As seen in the studies discussed above (Zamir and Etzioni, 1999, Dumais et al., 2001, Käki, 2005c, Kules and Shneiderman, 2008), participants delved deeper into the results list (with reference to the original ranking) when they used the grouping interface, and they saved more documents per query when using the grouping mechanism.
Most clustering algorithms end up with at least one “miscellaneous” cluster where documents that do not fit well into the remaining clusters end up. Zamir and Etzioni, 1999 refer to these less coherent clusters as index clusters, and found in their logs that users clicked on these less-coherent groups about 21% of the time (although they could not discern if users benefited from following these links or not).
8.8.3: Clustering on the Web
Over the years, a number of Web sites have supported cluster-based search results. Although these algorithms are not published, they appear to be a variation of monothetic clustering.
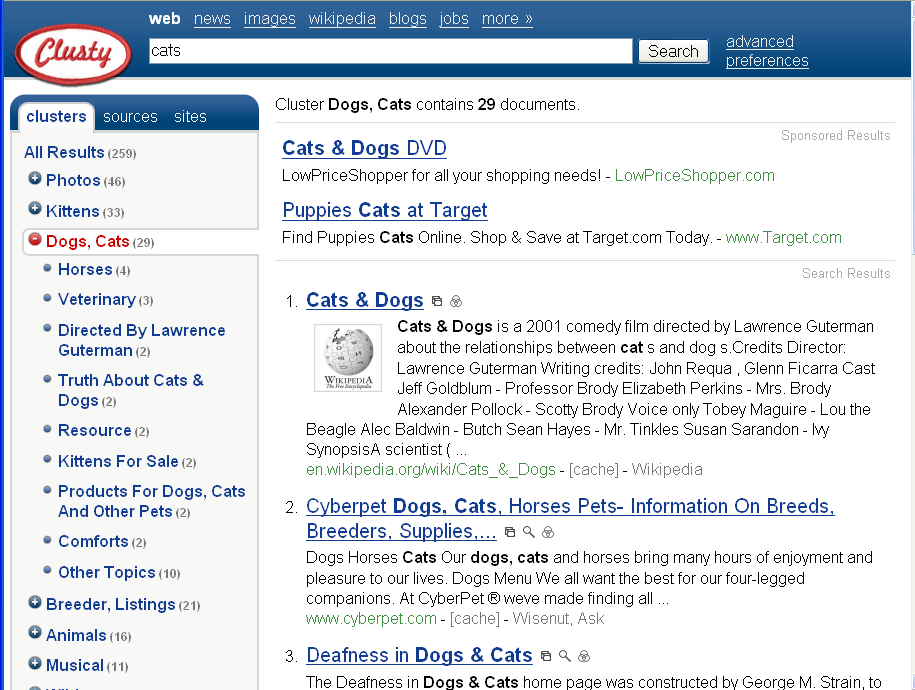
Figure 8.19 shows results for the query cats using the Clusty.com search engine (from Vivisimo.com), with the cluster named Dogs, Cats expanded. The topmost clusters are labeled Photos, Kittens, Dogs/Cats, Breeder Listings, Animals, and Musical. Note that, although one can infer the meaning of these labels, they are somewhat disorganized and vary widely in level of description (kitten is a kind of cat, and cat is a kind of animal, and all three levels are seen as cluster labels). The subclusters within Dog, Cat include horses, names of films with animals in them, general terms like Resource, and kittens for sale, despite the fact that the cluster above this one is named Kittens. Thus, the list of topics is not particularly coherent, and the subclusters often confusingly repeat topics from the clusters above. The example results for the iBoogie clustering engine shown in Figure 8.20, when run on the same query, appear to have more coherent labels. These systems tend to produce better results when focused within a topic domain. Figure 8.21 shows the results of the technology behind Clusty applied to a biomedical collection, on the query tinnitus.


8.9: Clusters vs. Categories in Search Interfaces
This chapter has discussed methods for organizing search results, and integrating navigation and search. The two primary methods for this are category systems and document clustering. This section discusses the relative advantages and disadvantages of each approach (following the arguments of Hearst, 2006a).
Clustering methods have the notable advantage of being fully automatable, and thus applicable to any text collection, but at the cost of consistency, coherence, and comprehensibility. Category systems provide a logical and consistent organization on a document collection, and have been shown to be superior to clusters and flat lists in usability studies (Dempsey, 2006, Dumais et al., 2001, Kules and Shneiderman, 2008, Pratt et al., 1999, Yee et al., 2003). However, categories require manual curation, may not fully reflect the topics within the collection, and documents need to be manually assigned to categories (and automated methods are about 75% correct on average) (Sebastiani, 2002). The disadvantages of polythetic clusters for user interfaces include their lack of predictability, their conflation of many dimensions simultaneously, the difficulty of labeling the groups, and the counter-intuitiveness of cluster subhierarchies.
Clustering algorithms can be more responsive to the idiosyncrasies of a given query's retrieval results. For example, in September 2005, shortly after the devastation wreaked by Hurricane Katrina, a query on New Orleans at Clusty.com produced a top-ranked cluster labeled Hurricane, followed by the more standard clusters labeled Hotels, Louisiana, University, etc.
By contrast, categories present well-understood and predictable meaning units. For example, in Google Co-op, a query on the name of a travel destination such as New Orleans produces a standard list of categories such as Dining, Lodging, Attractions, Shopping, Transportation, and so on.
Clustering can be useful for clarifying and sharpening a vague query, by showing users the dominant themes of the returned results. Clustering also works well for disambiguating ambiguous queries, particularly acronyms. For example, ACL can stand for Anterior Cruciate Ligament, Association for Computational Linguistics, Atlantic Coast Line Railroad, etc. A clustering algorithm will group together those documents that contain the same long form of the acronym. However, because not every document will use the long form of the acronym, and because clustering algorithms are imperfect, they do not neatly group all occurrences of each acronym into one cluster, nor do they allow users to issue followup queries that only return documents from the intended sense (e.g., “ACL meeting” will return meetings for multiple senses of the term).
By contrast, a category system will neatly and consistently place the anatomical sense of ACL within a medical category, and the computational linguistics sense within a technical category. However, if the automated category assignment algorithm has not been exposed to training data containing acronyms, it may not be able to properly assign documents that do not contain the long form.
Clusters are also useful for eliminating groups of documents from consideration. This result is supported by participants' comments found in several studies (Kleiboemer et al., 1996, Käki, 2005b, Hearst and Pedersen, 1996). For example, if most documents in a set are written in one language, clustering will very quickly reveal if a subset of the documents is written in another language. Categories can of course be used to eliminate or ignore irrelevant topics as well.
A primary problem with clusters, especially polythetic clusters, is that their contents can be difficult to understand. One study found that for non-expert users the results of clustering were difficult to use, and that graphical depictions (for example, representing clusters with circles and lines connecting documents) were much harder to use than textual representations (for example, showing titles and topical words, as in Scatter/Gather), because documents' contents are difficult to discern without actually reading some text (Kleiboemer et al., 1996).
Another major problem with polythetic clustering systems is that the subdivision produced by hard clustering (where documents appear in only one cluster) forces choices about where to place documents: should the article on government controls on RU486 be placed in a cluster on pharmaceuticals, or one on women's rights, religion, or politics? Documents are simultaneously about many concepts.
Faceted category systems allow the user to easily navigate according to several different topics; clustering is usually limited to just one topic. Category systems also lend themselves well to navigation within is-a hierarchies. Most clustering interface studies do not assess usability of the hierarchical aspect of the clusters, but the available online systems do not produce readily understandable results, as seen in the Clusty.com discussed earlier.
In fact, those studies that do compare categories to clusters find that categories prevail. In a study examining image collection presentation, Rodden et al., 2001 found that participants preferred images organized by meaningful categories over images clustered by visual similarity. As mentioned above, a usability study comparing the Dynacat system, which organizes results into a pre-determined category hierarchy, was preferred by participants over a linear list and a polythetic clustering interface (Pratt et al., 1999). Chapter 10 reports on the results of additional usability studies on visualization of document clusters. In all cases, the results are negative.
8.10: Conclusions
As seen in several discussions throughout this book, an oft-preferred method of search makes use of small steps that allow users to retain the context of their activities. Navigation structures are useful both for imposing an organization on retrieval results, and for re-ordering, narrowing, and filtering those results. An information structure can also provide a useful starting point for getting to know a collection of information.
This chapter has discussed an extensive range of approaches to providing navigation structure and integrating it with keyword search. Methods covered include category systems (flat, hierarchical, and faceted), TOC views, and automated clustering techniques. It was seen that although hierarchical organization can work for some smaller collections, faceted navigation with query previews has been found to be highly successful for searching within a wide range of information collections. It was also seen that although clustering has the advantage of being fully automatable, the results tend to be difficult for users to understand, although the more recent focus on monothetic clusters is more promising than the earlier predominant polythetic clusters. Faceted navigation has the drawback of requiring the category structure to be designed and assigned to items, although automated methods are under development. Most likely in future, hybrids with somewhat more flexible information structures will be explored.