Ch. 12: Emerging Trends in Search Interfaces
This chapter describes several areas that are gaining in importance and are likely to play a significant role in search interfaces in the future. These predictions come primarily from extrapolating out from emerging trends. The areas that seem most likely to be important, and so demand changes in search interface technology, are: mobile search, multimedia search, social search, and a hybrid of natural language and command-based queries in search. Each is discussed in detail below.
12.1: Mobile Search Interfaces
Mobile communication devices are becoming increasingly popular as information access tools. A recent survey of more than 1,000 technology leaders and other stakeholders said they expect that mobile devices will be the primary connection tool to the Internet for most people in the world in 2020 (Rainie, 2008). They also predict that voice recognition and touch user interfaces will be more prevalent and accepted by 2020. Usable interfaces for search on mobile devices are only now beginning to emerge, but this area will most certainly undergo rapid development and innovation in the next few years.
Until recently, mobile devices had small screens, awkward text input devices, and relatively low bandwidth, which pose challenges for information rich applications like search. However, bandwidth is increasing, and the recent appearance of personal digital assistants (PDAs) with relatively large, high-resolution screens, such as the Apple iPhone, are making search on mobile platforms feel more like desktop-based Web search.
The following sections discuss how mobile search interfaces differ from those of desktop search, including how mobile query intent differs from general Web queries, specialized techniques for query specification, and techniques for viewing retrieval results that have been developed for mobile devices.
12.1.1: Mobile Search Usage Patterns
Researchers and technologists have suspected that, for mobile devices, the context of use may strongly influence the kinds of information seeking tasks the user is likely to engage in. For example, it has often been proposed that temporal and geolocation information can be used to better anticipate mobile users' information needs (Kaasinen, 2003, Sohn et al., 2008). A standard example is a query such as “Find a reservation for one half hour from now at a restaurant that is less than one mile from where I am standing.” Route-finding tasks, planning tasks, and informational queries relevant to the current location have been predicted to be more likely than other kinds of queries for users of mobile devices, and mobile search interfaces have become tailored towards these anticipated modes of use. The studies of mobile information usage described below support these hypotheses.
To address the question of how information seeking from small portable devices differs from desktop search, Kamvar and Baluja, 2006 studied a set of more than 1 million page view requests to the Google mobile search engine (see Figure 12.1) from cell phones and PDAs during a one month period in 2005. Among other things, they found that average query length was less for cell phones than PDAs, and both of these were shorter than desktop-based search queries on average. They also found less variation in queries issued on small devices. When they looked at a random sample of 50,000 queries, the most frequent 1,000 queries for the cell phone searchers comprised 22% of all the queries, whereas the most frequent 1,000 desktop (personal information) queries accounted for only 6% of all desktop queries. They also classified queries into topics, finding that “adult” queries were the most frequent for cell phones at greater than 20%, but were about 5% for the PDA queries, which is similar to Web search today. Since Web search has seen a rapid decline in adult queries as a proportion of all queries over time (Spink et al., 2002), they speculate that the prevalence of adult queries in cell phones reflects both their novelty and their perception as a personal, private devices. This is in contrast with PDAs which are often used in a business context.

Kamvar and Baluja, 2006 also examined properties of session usage and clickthrough, finding that both PDA and cell phone sessions had significantly fewer page views per query than desktop search. For cell phone queries, they found that 28% of queries within a 5 minute session window were reformulations, 14% were responses to spelling suggestions, and 32% were repetitions of the original query. Thus in most cases, users came to the system with a specific information need and did not stray or explore other topics. These results are not surprising given the relatively slow bandwidth of mobile devices at the time and the fact that some services charge according to the number of bytes transmitted.
Sohn et al., 2008 conducted a diary study in which they asked 20 people to record their information needs while mobile over a two week period. Participants were asked to send a text message to a special email address whenever they felt a desire to acquire some information, regardless of whether or not they knew how to obtain that information. Sohn et al., 2008 created a taxonomy of information needs, the most common of which were “trivia” (answering questions that came up in conversation, such as “What did Bob Marley die of and when?”), directions, points of interest (“tell me about a place and then give me directions to it”), information about friends, business hours, shopping, and phone numbers. In total, 72% of the information needs were contextual in nature, where context can be defined as current activity, location, time, and conversation. Thus this study lends further support to the idea that mobile search benefits from using personal and contextual information.

(a)

(b)
12.1.2: Query Entry on Mobile Devices
For the smallest mobile devices, text entry is accomplished by 12-key input devices requiring up to three clicks per letter. Larger handhelds such as Blackberry devices allow for “thumb typing” on small physical keyboards, and more recently touch-screen interfaces such as that seen on the Apple iPhone allow for tapping on a virtual keyboard on the screen. Nevertheless, these techniques are slower than typing on a full keyboard. The techniques described below can help improve query entry.
Dynamic term suggestions: One way to speed up text entry is to use previously popular queries to generate statistics for auto-completion of query terms (Buyukkokten et al., 2000a) (also known as dynamic term suggestions). Yahoo OneSearch provides this functionality on some mobile phones, showing suggested queries to complete what the user has typed so far (see Figure 12.2). (See Chapter 4 for a discussion of auto-completion of query terms in non-mobile interfaces.)
Anticipate Common Queries: Another way to simplify query entry is to know the kind of query that might be asked in advance. This can be used to reduce typing by allowing for abbreviated, command-like queries for a limited set of commonly executed actions. In the Google SMS text messaging system, users can send a short command and receive a text message in response with a short answer. For example, a query such as “pizza 10003” returns short descriptions of nearby restaurants based on the zip code, and “price ipod 20g” shows competitive price information while shopping (Schusteritsch et al., 2005). Yahoo OneSearch supports similar kinds of queries, but focuses on providing “instant answers” -- specially formatted answers to questions, rather than standard results listings, using the graphical display available on advanced handheld devices. Thus, a search on ping pong returns a vertical listing divided into main categories including products, images, Web sites, news articles, Wikipedia, and Yahoo Answers (see Figure 12.2). A few hits from each category is shown along with a link to see more. A link that appears at the top of the additional listings page allows the user to return back to the main results page.
Spoken Queries: Voice-controlled computers have been a dream of technology developers and users for many years, and very recently, the major search engines have introduced mobile phone-based voice-entered query terms. These work for answer-based or command-like queries discussed above, including searching for local information such as nearby restaurants, looking up current airline flight information, zip codes, and video search, but are also used for general keyword queries and Web results. In these interfaces, the user indicates they are starting a query by, in the case of Yahoo on Nokia, holding a special Talk button on the phone, or more recently, in the case of Google Mobile on the iPhone, using motion sensors on the phone to activate the speech recognition technology when the phone is moved from the user's waist-level up to their ear. Usually in these interfaces, search results are shown as text on the screen, although some specialized queries show tailored results displays. For instance, Tellme's mobile search (now owned by Microsoft), uses GPS mechanisms on the phone to sense the user's current location, so that a query on coffee returns a map showing nearby coffee shops. Travel directions, movie listings, sports scores, and other context-sensitive information are shown in response to simple voice commands such as movies. The accuracy of the voice recognition for entered queries has not yet been reported, but benefits by being trained on many millions of queries from query logs (Markoff, 2008). As more people use the voice interfaces, more training data will accumulate on the voice data itself, and the interfaces will further improve.
As a more radical, but less scalable alternative, the ChaCha.com search system employs human experts to answer user's questions, entered either as text messages or voice questions. The user must wait a few minutes to receive an answer, which is looked up by a human using an online search system and is sent via text message.

12.1.3: Presenting Retrieval Results on Mobile Devices
Web pages designed for large screens do not necessarily translate well to small screens, and considerable research has gone into developing alternative methods of presenting the content of Web pages themselves to better accommodate the small screens and slow bandwidth commonly experienced in mobile computing (Xiao et al., 2009, Buyukkokten et al., 2000b, Bickmore and Schilit, 1997, Wobbrock et al., 2002, MacKay et al., 2004, Björk et al., 2000, Lam and Baudisch, 2005). For example, MacKay and Watters, 2003 analyzed four methods of transforming information content from large to small devices: direct migration, data modification, data suppression, and data overview. They analyzed the impact of each method on browsing, reading, and comparing information.
Despite the work in content transformation, to date mobile search interfaces vary little from that of desktop search (Church et al., 2006), although the formatting for instant answers as shown in Figure 12.2 is an advance. Commercially, Apple's Safari browser has been optimized to work well with small screens such as that of the iPhone.
Interfaces for search results display are a different matter. Some research papers address how to improve search for small devices, but most of this work focuses on experiments attempting to determine how much information should be displayed in search results for small devices. Sweeney and Crestani, 2006 conducted a controlled experiment to determine the effect of smaller screen sizes on search results interpretation. They compared what they call micro displays (mobile phones, smart phones), small displays (PDAs, Pocket PCs), and normal sized displays (desktop PCs and tablet PCs). In their between-subjects study design, each participant worked with only one device, and had to make a relevance judgement for each document presented for each pre-specified query. The participant first was shown the title of the document, and then could choose to expand the surrogate to include the first 7% of content, then the first 15%, and then the first 30% (see Figure 12.3).
The authors hypothesized that larger screens would lead to higher accuracy, and while they did see a decline in accuracy with decline in screen size, the differences among device sizes were not significant. The authors also hypothesized that participants using larger screens would choose to see more content, and that more content would produce better results. They did find that larger screens resulted in more requests for content, but they also found that more content did not produce better results. Participants, regardless of device, performed better on precision and recall measures with smaller amounts of context. The title alone achieved the highest precision scores, while title plus the first 7% of the document was best for recall. Increasing to 15% or 30% of content did not help with the relevance assessments. It should be noted, however, that the evaluation was performed with TREC queries, which tend to be complex and are probably not representative of what people want to query on while mobile. The authors also noted that the participants seemed to be much better at excluding irrelevant documents than they were at picking out the truly relevant documents, as recall was very low.

Two recent papers describe the benefits of converting the format of the content to better reflect search results. Xie et al., 2005 experimented with four different representations of web page content for search result presentation on smart phones and Pocket PCs. They applied an algorithm that decomposes a Web page into blocks that are labeled according to three levels of importance: main content; useful information but not central to the main points of the page, including navigation bars; and unimportant information such as ads, copyright declarations, and decorations. They then evaluated four conditions: (1) The original page. (2) A thumbnail view which showed the original page but divided into blocks, each of which can be navigated to, selected, and its contents then shown in a zoomed-in view. The predicted importance of each block is indicated by showing graphically the number of query terms in each block and color coded according to predicted importance level. (3) An optimized one-column view that sorts the blocks in descending order of importance and then reformats them to avoid horizontal scrolling, and (4) A main content view which just shows the contents of the most important blocks, formatted to avoid horizontal scroll.
Twenty-five participants performed searches in a within-subjects design. Both task and interface affected the search time. The main content view was the fastest, averaging 9.4 seconds per query on the Pocket PC, followed by the optimized one column view (11.0 s/q), the standard view (31.3 s/q) and the thumbnail view (33.3 s/q). The subjective scores also favored the one-column views. The authors speculate that the thumbnail view suffered from a complicated interface and that the overview approach may hold merit despite these results.
In a similar study, Rodden et al., 2003 compared a standard mobile search interface in which the user sees a version of the Web page that mimics that seen in a standard browser, thus requiring horizontal and vertical scrolling, with an alternative that segments the page and graphically shows the number of query term hits within each segment. After some pilot studies, they decided to use two yellow squares to indicate the region of a page with the most query term hits, while all other regions with at least one hit received one yellow square. An interesting innovation is the display of numbered tabs on the right hand side that correspond to the top 10 search results (see Figure 12.4).

They conducted a usability study to examine participants' ability to spot the answer to a question on a single retrieved page. They intentionally designed some questions to perform well in their interface, while other tasks were expected to perform poorly on their design (for example, placing the answer far enough down the view that it would require scrolling). They found no main effect of browser type, but did observe significant effects between browser and task type, reflecting the relative appropriateness of each browser. Subjective reactions strongly favored the segmented approach.
In a similar finding, Lam and Baudisch, 2005 found that preserving the screen layout in a thumbnail view while highlighting terms important to the information need resulted in faster times for finding specific information within a Web page than with a single-column view or a standard thumbnail.
Moving from search to navigation, the Fathumb (Karlson et al., 2006) interface uses faceted categories and information visualization for a navigation-based method for accessing an information space, such as a travel guide (see Figure 10.26 in Chapter 10). Each facet is represented by a position within a 3x3 grid. Pressing a number on the keypad selects and enlarges the associated facet category; internal tree nodes drill down to the next hierarchical level, while leaf nodes expand to occupy the entire navigation region. Bainbridge et al., 2008 created a browsing interface for the Apple iPod music player, which has very limited interaction controls and no keyboard (physical or virtual). They converted a digital library to a hierarchical structure and made it navigable using the thumbwheel control that characterizes the iPod (see Figure 12.5).
As mentioned previously, another way that search results display is changing is by showing specialized interfaces for particular question types, such as showing maps with locations of restaurants in response to a query on restaurant location. Specialized site search, such as Powerset's interface for viewing Wikipedia encyclopedia search results, are being well-received for larger-screen mobile devices like the iPhone.
12.2: Multimedia Search Interfaces
Images, video, and audio information objects are increasingly important to the information landscape. The ease of creation, storage, and distribution of digital video and audio over the last few years has created a boom in their use. A Pew Research survey conducted during January 2008 reported that 48% of Internet users had used a video-sharing site such as YouTube, and 15% said they had used such a site on the previous day (Pew, 2008a). A media executive reported that email offering podcasts of conferences was opened about 20% more frequently than traditional marketing email (Ranie, 2006).
Although this book focuses primarily on user interfaces for searching textual information, it is highly likely that audio, video, and image search will take on an increasingly important role in the coming decade. With improvements in spoken language recognition, it may become the case in future that keyboard typing will disappear entirely, with text being entered exclusively by voice. Video over the Internet now supplements the U.S. President's weekly radio address. Movies have replaced books as cultural touchstones. And people in the developing world may skip textual literacy altogether in favor of video literacy.
However, the technology for search over multimedia lags far behind that of text for its creation, storage, and distribution. This is primarily because automatic image recognition is still a largely unsolved problem. Automatic speech recognition is greatly improved, which allows for the new spoken-query input techniques described in the previous section on mobile search, but more advances are needed to achieve universal transcription of long spoken audio documents. Furthermore, the text that is associated with video is often not particularly descriptive of its contents. Hauptmann et al., 2006 write:
“Despite a flurry of recent research in video retrieval, objectively demonstrable success in searching video has been limited, especially when contrasted with text retrieval. Most of the mean average precision in standard evaluations can be attributed to text transcripts associated with the video, with small additional benefit derived from video analysis.”
Nonetheless, given the growing importance of this form of interface, it is likely that improvements will be made over the next few years. The following sections briefly describe the state of the art in user interface development for multimedia search.

(a)

(b)
12.2.1: Image Search Interfaces
Image search techniques that attempt retrieval based on the bits representing image or video data are referred are to in that field as content-based retrieval, to stand in contrast with keyword retrieval. One of the best-known early image retrieval systems, QBIC, represented images by color histograms; that is, a count was made of how many pixels in the image contained each color, using a color space representation such as Munsell color coordinates (Flickner et al., 1995). A query could consist of an image, and other images with similar color distributions would be retrieved. Alternatively, a user could select a set of colors from a color palette, and indicate the desired percentage. QBIC also allowed querying against texture samples and general shapes. Figure 12.6 shows an example in which the user has painted a magenta circular area on a green background using standard drawing tools, and query results are shown below in a grid view (Flickner et al., 1995). For a query specifying both color and shape, the matching algorithm tries to find images with a centered magenta shape surrounded by a green background, such a roses in a field. QBIC also allowed for search over image stills derived from video content.
One drawback of query-by-example for images is that it requires the searcher to know a great deal about the visual property of the image they are searching for, which can be helpful for known-item search but is usually not the case when looking for new images. Another drawback is that it can be quite difficult to successfully specify the colors and shapes in order to retrieve the desired object.
Relevance feedback techniques (see Chapter 6) have been applied to image and video search (Rui et al., 1998). Users are asked to scan a grid of images and mark those that new retrieved images should be similar to (and in some cases, different from). The image retrieval algorithm computes similarity of the marked images to other images in the collection, using a weighted combination of attributes of the image, such as color, texture, and shape.
A commercial Web site, Like.com, provides everyday users with the facility to search for products based on similarity to visual properties, within a faceted navigation framework. The user can draw a rectangle around a portion of a selected product's image and choose to refine the query by either the represented shape, color, or both (see Figure 12.7). This kind of visual relevance feedback sometimes works well, but often brings back unexpected or confusing results. As in text search, relevance feedback tends to work better when the user selects multiple objects as being relevant, as well as indicating which objects are not relevant. But more generally, image retrieval using purely visual measures has so far had limited success (Rodden et al., 2001). Rather, as discussed in Chapter 8, faceted navigation works well for image navigation and search when the appropriate category labels and textual descriptions are available, and is the preferred method for image navigation and retrieval today, along with keyword search used in web image search interfaces (described below).

There have been numerous interfaces developed for browsing of small personal image collections (Kang and Shneiderman, 2000, Bederson, 2001, Graham et al., 2002), including many attempts at using image clustering as an organizational framework (Platt et al., 2003a, Cai et al., 2004) (which has been shown to be confusing in usability studies (Rodden et al., 2001) ) as well as some work on aiding in the automated annotation of image and video collections (Shneiderman and Kang, 2000, Abowd et al., 2003).
12.2.2: Video Search Interfaces
For video retrieval, the data is first segmented into higher-level story units or scenes, and then into shots, where a shot is a video sequence that consists of continuous video frames for one camera action (Zhang et al., 2003). From within the shot, one or more key frames is selected to represent the shot in search interfaces and for matching purposes. If text is associated with the video segments, as in a spoken transcript for television news, the text is indexed to correspond with the temporal aspects of the shots.
Until recently, most of the innovation in video retrieval was focused on the underlying algorithms for analyzing, storing, and efficiently retrieving the data, with less emphasis on the search interfaces. However, the TREC Video track and its successor, the TRECVID competition (Smeaton et al., 2004), have brought more attention to the interface aspects of video retrieval. Figure 12.8 shows the query and retrieval interface for an interactive video search system (Adcock et al., 2008).

There has recently been a realization that the algorithms cannot do as well as interactive systems that allow users to quickly scan a large number of images and select among those. This differs from text retrieval in that people can scan images much more quickly than they can read lines of text. Hauptmann et al., 2006 write:
“Interactive system performance ... appears strongly correlated with the system's ability to allow the user to efficiently survey many candidate video clips (or keyframes) to find the relevant ones. The best interactive systems allow the user to type in a text query, look at the results, drill deeper if appropriate, choose relevant shots for color, texture and/or shape similarity match and iterate in this by reformulating or modifying the query.”
Hauptmann et al., 2006 also note the increasing popularity of what is known as Rapid Serial Visual Presentation (RSVP) techniques, in which the user is presented with a series of images, one replacing the next in the same place on the screen, to eliminate the need for eye movement, and so make scanning of images faster (Spence, 2002) (this approach is also being investigated for mobile interfaces (Öquist and Goldstein, 2003) ). Researchers are exploring many variations on the RSVP browsing technique in which images travel in a path across the screen and images in addition to the focus image are shown (Wittenburg et al., 2003). Another mechanism for laying out video shot search results is seen in the ForkBrowser interface (Snoek et al., 2007, de Rooij et al., 2008), which was found to reduce the number of steps needed and increase the number of relevant shots viewed in a small usability study (see Figure 12.9).

Relevance feedback is a popular method for experimental video retrieval systems, but it has been shown that simply retrieving shots that are temporally near shots that are already marked relevant can be nearly as effective (Hauptmann et al., 2006).
12.2.3: Audio Search Interfaces
Audio in search can be used both as an input modality, as in spoken queries, and as a media type to search over. Kohler et al., 2008 note a “renaissance” in speech retrieval in the last few years, due both to the increased availability of podcasts and other audio and video collections, and to the maturing of speech recognition technology. Although much of the audio retrieval research has been done on broadcast news, the availability of digitally stored casual speech in the form of interviews, lectures, debates, radio talk show archives, and educational podcasts is increasingly available. However, searching conversational speech poses additional challenges over professional speech (Maybury, 2007). Music retrieval is also an active area of research (McNab et al., 1996, Downie, 2003, Vignoli and Pauws, 2005, Mandel et al., 2006).
Because spoken language audio can be converted with some degree of accuracy to text, audio retrieval interfaces can be more similar to those of text retrieval than image and video data, although in some cases, such as voicemail retrieval, the nuances in spoken language are the important part of an audio message, and for these text transcripts are insufficient (Whittaker et al., 1998). Nonetheless, some researchers have experimented with creating visual interfaces to speech archives. For example, the SCAN (Speech Content Based Audio Navigator) system (Whittaker et al., 1999) provided a scannable interface for searching an archive of the audio of broadcast news (see Figure 12.10). In a study with 12 participants, participants were more successful and preferred an interface with a visual component showing location of query term hits, even though they were searching over audio content.

Tombros and Crestani, 2000, in a study with 10 participants, compared retrieval results presented as text on a screen versus read aloud by a human in person, read by a human over the phone, and read by a speech synthesizer over the phone. The phone-based systems were significantly slower than the on-screen system, and less accurate as well. They found that precision, recall, and time taken for the last query when hearing information over the phone was significantly slower than for the first query in that condition, but did not find this in the screen reading condition.
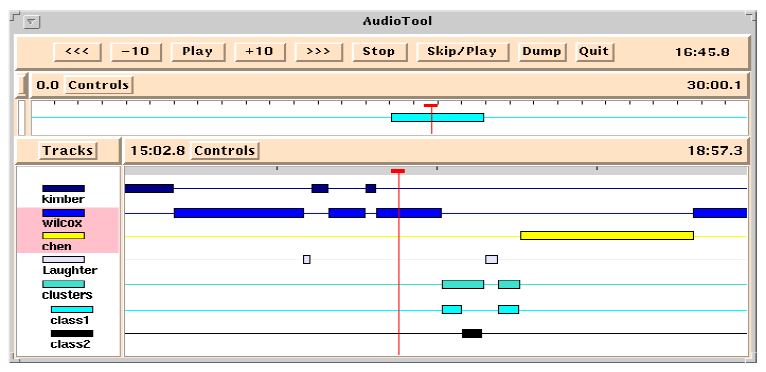
Some researchers have focused on speaker recognition algorithms and interfaces to show who is speaking at different points of time in a meeting or other group situation (see Figure 12.11) (Kimber and Wilcox, 1997). Many efforts in this domain are multi-modal, meaning that audio, text, and video are interlinked and cues from each are used to segment and recognize different attributes from each media type (Bett et al., 2000, Oviatt et al., 1997, Oviatt and Darrell, 2004, Maybury, 2007).
12.2.4: Multimedia Search on Web Search Engines
Web search engines have long offered search over images as well as text, and more recently have begun offering video search as well. Most search engines offer multimedia search as an explicit search starting point, activated when the user selects a tab or a link from the main search page. Thus if a user selected Image Search and typed in rainbow, the results would look much different than querying on the same keyword in Web search. Additionally, for many years, if the user included image or pic as part of the query, the search results would suggest that the user switch over to image search. When implemented this way, the multimedia search is referred to as a vertical search, meaning search over a specialized or limited collection.
Recently the major search engines have introduced what they call blended results or universal search, in which hits on images, videos, news, and other kinds of specialized content are interwoven with the Web page hits in the search results listing. (But only those queries that the algorithm determines should have such hits; many queries bring up only Web page hits.) A survey by iProspect of 2404 adults found that when multimedia search is offered as a vertical that requires changing the search interface, a large proportion of users either do not use it (35%) or else do not recall clicking on a link after using it (25%). Of those who have used vertical search, 26% recall having clicked on an image result, 17% on a news result, and only 10% on a video result. However, in the approximately six month period between when blended results were introduced by the major search engines and when the survey was conducted, 81% of users reported having clicked on these specialized links in the blended results, with news results being the most popular (iProspect, 2008). Eye-tracking results also indicate that including an image within the search results page tends to alter the scanning pattern (Hotchkiss, 2007a).
For Web search engines, image search is primarily keyword search, based on text labels derived from anchor text and/or the text surrounding the images on the Web pages in which they appear. Image search engines can also make use of human-assigned tags, as used in the Flickr photo sharing Web site. In most cases, the user enters a query into a search form, and the images are shown in a grid, labeled with some metadata. Microsoft image search uses an “endless scroll” grid interface, meaning that rather than breaking the results up into pages of 10, 30, or 50 images, all the images are shown in one continuously growing web page, progressively appearing in the grid as they are retrieved. Image analysis technology is used to allow the user to refine by certain attributes that can be easily computed, such as image size, aspect ratio, color versus black and white, and photograph vs. illustration. The system also runs a face recognizer so users can refine images to those that contain people. Flickr also allows search over images according to manually assigned geographic location tags, showing the locations of resulting images on a map.
Video search on the Web is also based on text, but currently primarily based on titles assigned to the video. It currently is not possible in most cases to search by director or creator of the video. On more curated video search sites, such as the Prelinger collection at the Internet Archive, videos have been labeled with metadata, and so keyword searches can be refined by creator, date, and viewer ratings (see Figure 12.12). The video's content is suggested by a series of thumbnail still images extracted from the video. The commercial video search site Blinkx claims to use speech recognition and video analysis in addition to searching the text of the metadata.
A simple form of audio search is offered by Yahoo, but not the other major Web search engines. There are podcast search services offered online such as Podscope that appear to use speech recognition technology to extract terms to search over.

12.3: Social Search
In physical libraries, librarians have traditionally acted as a mediator between a client with an information need and the physical or computer catalog system (and now some libraries offer online chat services with a librarian during working hours). With the arrival of automation, the focus of search engine development shifted to individuals searching on their own, and most interfaces discussed in this book are designed for an individual user. However, with the rise of the interactive Web (“Web 2.0”), in which people interact with one another, variations on what might be called social search are becoming increasingly popular and promise to play an important role in the future of search. The following subsections describe three manifestations of this phenomenon: social ranking, collaborative search, and human-powered question answering. These all have in common the use of the thoughts and efforts of multiple people to improve search or the search experience.
12.3.1: Social Ranking
As mentioned in Chapter 9, an increasingly popular way for people to find information serendipitously is through web sites like Digg.com and StumbleUpon.com that use the “wisdom of crowds,” record people's recommendations, and show the most popular information items at the top of the list. Social bookmarking sites, like Delicious.com and Furl.com, in which people record items they want to use later, also act as recommendation services. The use of social tagging and social bookmarks to improve ranking has begun to been explored (Heymann et al., 2008, Yanbe et al., 2007).
Also as discussed in Chapter 9, user clickthrough is being used by Web search engines today to adjust their ranking algorithms. This is a kind of implicit feedback, in that users click on the links because they think they are relevant, but not with the purpose of influencing the ranking algorithm in future. A related idea that has been investigated numerous times is that of allowing users to explicitly comment on or change the ranking produced by the search engine. This is akin to relevance feedback (see Chapter 6), but the difference is that the preferences indicated affect rankings shown in future for the user in question, and also potentially affect the search engine's algorithms for all users. Microsoft Research proposed a system called U Rank which allows users to move the rank position of hits, and Google has recently introduced SearchWiki which allows the user to move a search hit to the top of the rankings, remove it from the rankings, and comment on the link, and the actions are visible to other users of the system (see Figure 12.13). Experimental results on this kind of system have not be strongly positive in the past (Teevan et al., 2005b), but have not been tried on a large scale in this manner.
Another variation on the idea of social ranking is to promote web pages that people in one's social network have rated highly in the past, as seen in the Yahoo MyWeb system mentioned in Chapter 9. Small studies have suggested that using a network of one's peers can act as a kind of personalization to bias some search results to be more effective (Joachims, 2002, Mislove et al., 2006).

12.3.2: Multi-Person and Collaborative Search
There is an increasing trend in HCI to examine how to better support collaboration among users of software systems, and this has recently extended to collaborative or cooperative search. At least three studies suggest that people often work together when performing searches, despite the limitations of existing software (Twidale et al., 1997, Morris, 2008, Evans and Chi, 2008). Morris, 2008, from a survey of 204 workers at a large U.S. technology company, found that 53.4% answered “yes” to the question “Have you ever cooperated with other people to search the Web?” and of those who said “no,” 10.5% indicated that they had “needed/wanted to cooperate with other people to search the Web and had been unable to effectively do so.” The most common collaborative search strategies were to watch over someone's shoulder as they searched the web and suggest alternative query terms, and to email links to share the results of a Web search. (The Ariadne system (Twidale and Nichols, 1998), discussed in Chapter 7, attempted to make the “sharing the screen” aspect of collaboration more visual.)
Of the 109 survey respondents in Morris, 2008 who collaborated with others, the most common tasks involving collaboration were:
- Travel planning (28%)
- General shopping (26%)
- Literature search (20%)
- Technical information search (17%)
- Fact finding (17%)
- Social planning (13%)
- Medical information search (6%)
- Real estate search (6%)
It is interesting, but not surprising, that, with the exception of fact finding, these are complex information seeking tasks that require comparisons and synthesis. This task list suggests that richer tasks benefit from collaborative search. This meshes with the results of Pickens et al., 2008 (described below) that found much greater gains in collaboration on difficult tasks than on simple ones.
There have been a few attempts to design search interfaces specifically for collaborative search. Foley et al., 2005 designed a collaborative video search system in which still images of retrieved videos are shown on a computerized table display. Searchers were seated across from one another at the table while working on shared retrieval tasks. Foley et al., 2005 compared two versions of the search interface, with eight pairs of participants. In one design, searchers had to drag the images into a centralized location in order to activate the video, and when they did so, a sound was played, thus increasing the awareness of their partners of what they are doing. The second design utilized more efficient interaction: to activate a retrieved video, the searcher double-tapped on the image, which was a subtle action that might not be noticed by the search partner. The study found that searchers performed better in terms of precision and recall when using the first design in which they were made aware of what their partner was doing.
Amershi and Morris, 2008 built and tested a tool to make interactions with other searchers a collaborative activity. The main idea was to make the queries and results from one user's search visible to other users who had joined a search task. Their usability study asked groups of three people to complete search tasks, in each of three conditions: they each had their own computer, they all shared one computer with one participant acting as “driver,” or they all shared one computer, but with special software called CoSearch that allowed the two observers to contribute using mobile devices. Participants did best with, and preferred, the shared computer condition, and did nearly as well with CoSearch. There was also significantly higher perceived communication and collaboration in the shared conditions.
Pickens et al., 2008 took this idea further. They note that in other work the search algorithm does not respond to the fact that multiple queries are being issued to achieve the same goals. They assume that ideally the ranking algorithm should allow people to work at their own pace, but be influenced in real-time by the different teammates' search activities. But the different searchers should not step on one another's toes: if one searcher decides to issue a new query, others should not be interrupted in their trains of thought.
Pickens et al., 2008 describe an algorithm that combines multiple interactions of queries from multiple searchers during a single search session, by using two weighting variables called “relevance” and “freshness,” where both are functions of the ranked list of documents returned for a given query. Freshness is higher for lists of documents that contain many not yet seen documents. Relevance is higher for documents that closely match the query. The two factors are combined to counter-balance each other, and are continuously updated based on new queries and searcher-specified relevance judgements.
Pickens et al., 2008 assume a team of two people collaborating, and assign one the role of Prospector, who is in charge of issuing new queries to explore new parts of the information space, while the other acts as Miner, whose job is to look deeply into the retrieved results to determine which are relevant. Documents that have not yet been looked at are queued up for the Miner interface according to the freshness/relevance weighted scores. The Prospector is shown new query term suggestions based on difference from queries already issued, and also based implicitly on the relevance judgements being made by the Miner. Each role has its own distinct interface, but a third computer screen is used to show continually-updating information about the queries that have been issued, the documents that have been marked as relevant, and system-suggested query terms based on the actions of both users.
In a study with four two-person teams, Pickens et al., 2008 compared results of the system in which the relevant documents were collaboratively determined versus a condition in which the queries were sent to a standard ranking algorithm that did not alter its behavior based on the activities of the two participants, but did produce a merged list of results. They found that collaborative search consistently outperformed the post hoc merging of the queries issued by the two participants. This result was especially strong for queries for which it was difficult to find relevant results.
12.3.3: Massive-Scale Human Question Answering
A relatively recent and quite surprising search interface phenomenon is the rise of human question answering sites, in which people enter questions, and thousands of other people suggest answers in nearly real time. The question-answer pairs are retained over time, and members are allowed to vote on the quality of the answers, so that the better answers move to more prominent positions.
In the Korean search market, human question answering is more popular than standard Web search (Ihlwan et al., 2006), perhaps in part because there is less information available online in the Korean languages than in English. However, the launch of Yahoo Answers was very successful in the English-speaking world, with more that 160 million answers after one year of service. One reason for the popularity seems to be the community-oriented aspects of these sites, allowing individuals to converse with one another. Another reason is the integration of user-generated answers into Yahoo and Google's search results. Some question the quality of the answers, finding them uneven, although there is evidence that community-supplied answers can be valuable (Agichtein et al., 2008).
A contrast is seen in the rent-an-expert approach in which experts answer difficult questions for a fee, as seen in the now-defunct Google Answers. The ChaCha.com Search service, in which human experts answer a user's question free of charge, has not become popular on the web, but is experiencing growth as a service for mobile device users. And companies continue to experiment with models of charging for online answers, as is currently available at the Mahalo.com Web site.
12.4: A Hybrid of Command- and Natural Language Search
As mentioned several times throughout this book, Web search engine algorithms are becoming more sophisticated in handling long queries as well as in attempting to discern the intent that underlies cryptic keyword queries. Right now they work by eliding some stopwords, and in some cases doing synonym substitution. As longer queries become more successful, people may try more “teleporting” queries more often -- stating their full information need in the expectation that the search engine can process it successfully. There are also a number of startup companies claiming to do natural language processing and “semantic” search. Some of these take a syntax-based approach to language interpretation, as seen in Powerset, while others attempt to achieve more deep semantics, as seen in Cognition.
A related trend is the use of using a flexible command syntax to create quasi-natural language interfaces. Norman, 2007b writes that “[S]earch engines have become answer engines, controlled through a modern form of command line interface.” Norman notes out that their syntax at major Web search is idiosyncratic and their coverage is spotty, but notes their virtues over command languages of old: “tolerant of variations, robust, and they exhibit slight touches of natural language flexibility.”
The Inky and Chickenfoot projects have implemented what they refer to as “sloppy commands” (Miller et al., 2008, Little and Miller, 2006), meaning the user has a lot of flexibility in how they express the command, and so memorization is not required to make use of them. The Enso system has implemented this idea in a robust manner for all operating systems. The Quicksilver application for Apple operating systems supports a hybrid command/GUI interface. They use continuous feedback to whittle down the available choices to include what the user has typed so far and that still matches available commands. The continuous feedback aids in the discoverability, lessening memory load.
It is likely that this hybrid between improved language analysis and command languages, making use of structured knowledge bases such as Metaweb's FreeBase, will be paired with clever uses of interaction, to lead to more intelligent interfaces and an expansion of dialogue-like interaction.
12.5: Conclusions
This chapter has discussed several areas that are likely to have a big impact on, or play a big role in, search in the future. The emphasis in this chapter is on mobile search, multimedia search, social search, and an increase in importance of natural language queries, at the expense of keyword search. Also worth mentioning are advances in search of verticals, such as travel information, health care information, government information, and blogs (Hearst et al., 2008), all of which can most likely be better served by specialized algorithms and interfaces. Search over intranets can still use improvement. Multilingual search, although sophisticated algorithmically, is not yet interesting from an interface perspective, but this may change with time. Local, or geographic information is being incorporated into many interfaces generally, including search, and especially into those for mobile applications.
Just as some displays are getting smaller, large displays with both projected views and touch-screen interaction will become cheaper and more prevalent. These will help facilitate collaborative information access as well as better support complex information analysis activities and visualization. Touch-screen displays may also change the dynamics of how people interact with search systems, and displays that project images onto tabletops or even into the air may enhance multi-person search efforts.
Of course, there is always the unexpected, unanticipated new development, and it will be exciting to see what that future brings to search user interfaces.